Reputation management is the ongoing process of monitoring, influencing and maintaining an entity’s public standing within digital information systems. Online reputation refers to the aggregate representation of an organisation or individual within search ecosystems as expressed through indexed content, review signals and algorithmic assessments.
Reputation management defines the set of practices and signals that determine how an entity is represented and evaluated inside search ecosystems. This topic analyses how content, metadata and external references form reputation signals, how algorithms interpret those signals, and how the resulting entity perception affects search visibility and stakeholder trust. The section explains the mechanisms that drive reputation formation, the search ranking consequences, and the operational implications for corporate governance and risk management.
Reputation management is a systems-level discipline that organises data flows, source credibility and content lifecycles to produce a coherent entity perception within search engines. It refers to the deliberate structuring and monitoring of public-facing information so that indexing systems and SERP evaluation processes can generate consistent, trustworthy signals about an entity.
How does search indexing create a digital reputation?
Search indexing defines which content about an entity becomes discoverable and how that content maps to entity identifiers. Indexing determines the base layer of a digital footprint and establishes the raw material from which reputation signals are derived.
Search indexing is the automated process by which crawlers retrieve, parse and store web content into a searchable corpus that algorithms query during SERP generation. It refers to the primary mechanism that converts web pages, reviews and structured data into retrievable signals about an entity within search ecosystems.
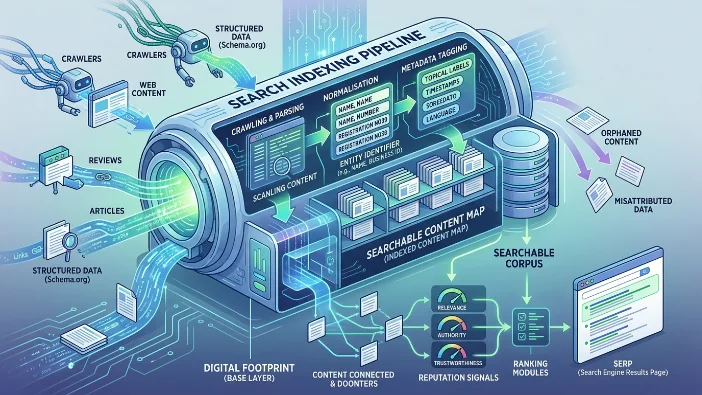
Crawlers follow links and sitemaps, record structured data (for example, schema.org entity descriptors), and normalise repeated identifiers (names, addresses, registration numbers) to connect disparate content to the same entity. Indexing pipelines tag content with contextual metadata — topical labels, timestamps and language — which subsequent ranking modules use to assess relevance and authority. Content that lacks consistent identifiers or structured metadata risks being orphaned or misattributed within the index.
Content that is consistently indexed and correctly associated with an entity increases the density of reputation signals, improving the chance that authoritative pages rank for entity-centric queries. Poor indexing results in incomplete digital footprints, which cause SERP evaluation to favour third-party interpretations and reduce direct control over entity perception.
How do algorithms interpret trust and credibility?
Algorithms operationalise trust through measurable proxies that correlate with quality, authority and intent. Understanding these proxies clarifies how search systems translate diverse inputs into reputation signals.
Algorithmic trust is the set of heuristics and learned models that evaluate the credibility of content and sources within search ecosystems. It refers to objective proxies — links, citations, review signals, topical authority and user interaction data — that algorithms use to infer trustworthiness.
Ranking systems combine link authority, topical relevance, on-page quality signals (structured data, content depth), and behavioural metrics (click-through rates, dwell time) to score pages. Algorithms apply entity recognition to connect these page-level scores to a central entity profile. Sentiment analysis and review aggregation modules quantify positive or negative signals, which feed into temporal weighting functions that prioritise recent, corroborated evidence. Models adjust for source reputation by weighting signals from known authoritative domains higher than unverified sources.
Entities with content that aligns with algorithmic trust proxies gain preferential SERP placements and richer knowledge panels. Negative or conflicting signals decrease perceived credibility, causing authoritative positions to shift away from primary sources and allowing third-party narratives to dominate SERPs.
How does content shape entity perception in SERPs?
Content defines narrative boundaries and topical context that search engines use when assembling entity-focused results. Precise content architecture controls the semantic map associated with an entity.
Content in this context is the indexed textual, multimedia and structured material that communicates facts, opinions and context about an entity within search ecosystems. It refers to the primary vehicle through which reputation signals are encoded and transmitted.
Search processors extract topic models and named-entity mentions from content, linking lexical patterns to entity attributes. Structured content (schema markup, canonical tags) clarifies relationships between pages and core entity pages. Topical depth and semantic breadth increase the number of entry points by which algorithms recognise relevance for different query intents. Content with consistent entity descriptors and corroborating references strengthens the semantic association between entity and topic.
Well-structured content creates a dense, coherent semantic footprint, which increases the likelihood of favourable SERP placement and accurate knowledge panel population. Fragmented or contradictory content reduces ranking stability and allows sentiment-rich third-party pages to have disproportionate influence during SERP evaluation.
What role do review signals and sentiment analysis play?
Review signals act as discrete reputation inputs that algorithms treat as direct indicators of stakeholder perception. Sentiment analysis converts qualitative feedback into quantifiable signals that influence entity perception.
Review signals are the aggregated ratings, textual reviews and platform-specific metadata that reflect stakeholder evaluations visible within search ecosystems. Sentiment analysis refers to automated classification of textual feedback into valence categories for algorithmic consumption.
Review platforms publish structured rating data that search systems ingest directly through APIs, structured markup and public indexation. Sentiment modules parse review text, normalise language variants and detect polarity trends over time. Aggregated scores feed into ranking heuristics and local search modules, while textual excerpts supply context used in SERP snippets and knowledge features. Platforms with verified review systems provide higher-weighted signals due to stronger provenance.
Positive, consistent review signals strengthen local and entity-specific SERP features and increase click-through probability. Negative sentiment trends generate prominence for corrective or critical pages, which alter entity perception during SERP evaluation and can depress overall search visibility for preferred content.
How do authority and trust signals operate across ecosystems?
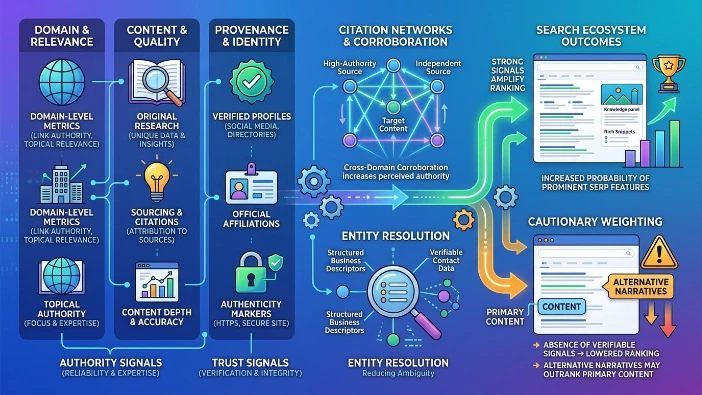
Authority and trust are multi-dimensional constructs assembled from corroborative evidence across domains, structured data and citation networks. Authority signals are indicators that a source or piece of content is recognised as reliable or expert within a topical domain. Trust signals are provenance and verification markers that establish authenticity and procedural integrity for content and profiles within search ecosystems.
Search systems assess domain-level metrics (link authority, topical relevance), content-level signals (original research, sourcing), and profile-level verifications (verified accounts, official directories). Citation networks that connect multiple independent, high-authority sources increase the perceived authority of linked content. Trust signals such as HTTPS, verifiable contact data and structured business descriptors reduce ambiguity during entity resolution.
Strong authority and trust signals amplify the ranking weight of associated content and increase the probability of occupying prominent SERP features. Absence of verifiable signals results in cautionary weighting, which allows alternative narratives to outrank primary content during SERP evaluation.
Dive Deeper With Our Expert Guides and Related Blog Posts:
How Your Business Reputation Affects Customer Trust and Revenue Growth
How Corporate Reputation in the UK Is Shaped by Search and Reviews
How does a digital footprint determine brand or entity reputation?
A digital footprint is the comprehensive set of indexed traces — pages, social references, reviews and mentions that collectively encode an entity’s public record in search systems. It defines the raw material from which reputation is inferred.
Digital footprint refers to all discoverable and indexed digital artefacts associated with an entity within search ecosystems. It refers to the ensemble of mentions, profiles, structured records and content that create a persistent representation of the entity.
Search engines aggregate footprint elements, normalise entity identifiers, and synthesise a profile used by ranking modules. Footprint density, topical relevance and source diversity determine the resilience of the entity profile. Temporal signals within the footprint allow algorithms to detect shifts and trends in perception, influencing the prioritisation of recent evidence during SERP evaluation.
A dense, consistent footprint increases control over how an entity appears in search results and reduces volatility in SERP outcomes. Sparse or inconsistent footprints increase susceptibility to misattribution, allowing high-engagement third-party content to dominate entity perception during searches.
For deeper insight explore:
How Reputation Management Works and What Results to Expect
This analysis defines reputation management as a system for generating, organising and monitoring reputation signals within search ecosystems and explains how indexing, algorithmic trust, content architecture, review signals, authority markers and digital footprints interact to produce entity perception and drive search visibility. Understanding these mechanisms clarifies why consistent identifiers, structured data, corroborated sources and coherent content architecture prove decisive during SERP evaluation. These elements collectively determine how search systems construct and present an entity’s reputation to stakeholders.
What is reputation management and why does it matter online?
Reputation management is the process of monitoring, influencing and maintaining an entity’s public standing within digital information systems. It matters online because search engines use reputation signals to determine entity perception and search visibility, which directly affects stakeholder trust and discovery.
How does corporate reputation management work for businesses?
Corporate reputation management works by systematically monitoring online mentions, optimising content for authoritative signals, and addressing negative information to improve SERP outcomes. It combines PR, SEO and risk management to shape how algorithms interpret trust and credibility for a business entity.
What are reputation signals and how do they affect search rankings?
Reputation signals are measurable inputs—such as reviews, backlinks, structured data and sentiment metrics—that algorithms use to evaluate an entity’s trustworthiness. These signals directly influence search visibility because Google ranks pages with stronger, consistent reputation signals higher in entity-focused queries.
How does online reputation impact customer trust and business growth?
Online reputation determines the entity perception stakeholders encounter during SERP evaluation, shaping whether customers perceive a business as credible and authoritative. A strong reputation increases click-through rates, improves conversion and reduces reputational risk during crisis events.